Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About
This is a page not in th emain menu
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
| Award | Year |
|---|---|
| Outstanding Technical Achievement Award (OTAA) | 2021 |
| Outstanding Technical Achievement Award (OTAA) | 2020 |
| IBM Service Corps Alumni | 2020 |
| IBM Invention Plateau | 2020 |
| Client Value Outstanding Technical Achievement Award(OTAA) | 2019 |
| Research Division Award | 2019 |
| Manager’s Choice Award | 2019 |
| Manager’s Choice Award | 2018 |
| Second Runner-Up in WSDM cup competition | 2017 |
| Insta Award for client success | 2015 |
Published:
Tool usage: R, SQL, CARET, NLTK
At Infosys, Jay worked for a European banking clients on projects related to Data Analysis and Machine Learning. He has experience working on different phases of end to end data science pipeline
Published:
Tools usage : R,Python,Markdown,Shiny,Spark,APIs
Jay worked at University of Illinois as a Research Assistent while pursuing his Master’s degree. His work was about finding answers to several media research questions by analyzing natural language/text on issues such as Privacy, Secrecy ,Immigration etc.During the course of research,he worked on multiple projects using text mining techniques such as topic modelling ,text classification,Named entity recognition,POS tagging,sentiment analysis and advanced ML techniques such as SVM,Xgboost,clustering methods etc.,
Below are the projects
1)”Privacy VS Secrecy analysis” using data from twitter feeds
2)”Immigration Analysis” with data from the New York times articles.
Git links of projects
Twitter Privacy VS Secrecy Analysis
NYtimes Immigration Analysis
Published:
In the summer of 2017, Jay worked at Mayo clinic as a Intern.There he was responsible to develop tools for data pipelines and enhance existing tools.
Tool usage: Python, Unix, Perl, Selenium, beautiful soup, pptx
At Mayo clinic, Jay worked on multiple projects and his major project was ‘Automated Gene Report Generation’.Goal of this project is to automate the patient gene report (.pptx format) generation. Creating these reports is cumbersome as gene data comes from various sources such as files, web sites etc., and genetic counselors required these reports for analyzing genetic variations.
As obtaining gene data from multiple sources, creating a power point gene report is tedious and often gene counselors spend hours in preparing these reports. So through this project Jay automated pptx document generation using python to save time (saved ~ 3 hours per report) such that gene counselors can spend more time with patients than to worry about making reports manually.
Other than his major project,Jay developed enhancements for a “Metabolic Modelling tool”.Also,Jay was part of Machine learning club at Mayo where he presented,discussed research work with peers.
Git links of projects:
flash_ppt
cobra_babel
Published:
Tool usage: Python, docker , OpenShift , pytorch, FastAPI
At present Jay is working as Advisory Research Engineer , developing AI solutions for enterprise automation using Machine Learning, Deep Learning, Natural Language Processing, Process Mining, and cloud-native tools. He created significant business impact for IBM by developing several AI solutions for products/platforms and lead several proof-of-concepts(POC) on AI use-cases with clients. Along with creating business impact his day to day work involves contributing to reserach papers and patents. Below are few example projects and POCs
Published:
Jay uses several tools for developing AI solutions. He has experience with the following
Published:
Jay has expertise in Machine Learning, Deep Learning, Natural Language Processing, Statistical Learning and Process Mining
Published:
Key Words: R,SQL Logistic Regression , LASSO , tf-idf
This project was done at Infosys and due to restrictions code is not available.Goal of the project is to build a classification model for a banking client to categorize customers into “Happy” or “Unhappy” categories based on email text and survey feedback
Below are the steps in the project
1) Data was queried using SQL and complied data set for the analysis with email text, survey feedback and target sentiment variable
2) Performed Feature engineering,data cleaning on email text,survey feedback in two steps i) For the email text used text mining methods such as regular expressions, tf-idf to convert raw text to numeric vectors and then used PCA (Principal Component Analysis) to obtain dense representation of features. ii) For the survey feedback,it represents scores to a set of questions in the range of 0-7 and this data has high proportion of missing values ,to handle missing data used NNMF (Non negative matrix factorization) to fill the missing scores. and later both these feature sets were combined with target variable to obtain training data set.
3) Modeled logistic regression for the binary classification of sentiment and to deal with over fitting techniques such as cross validation and regularization(LASSO,Ridge) were considered, used Accuracy as model evaluation metric.
4) Interpreted variable selection using odds ratio and LASSO model to find out influential variables and it turns out that some of the survey feedback variables are important in classifying sentiment where as the dense features from text could not be interpreted as they are the principal components.
5) Obtained the best model that has better accuracy and predicted sentiment on unseen customer data.
Published:
Key Words: R,SQL,Hive,Logistic Regression,Random Forests
This project was done at Infosys and due to restrictions code is not available.The Goal of this project is to predict whether a customer of the bank will default or not in near future, and help the bank to make a decision in the approval process of loan.
Below are the steps in the project
1) Identified the key variables for analysis by working together with banking domain Subject Matter Expert (SME) and documented the requirements
2) Studied the schema of database and wrote SQL queries to pull data from several tables in order to compile data set for the analysis
3) Performed data cleaning and manipulation such as deleting records with majority missing columns,created new variables from existing variables like maximum transaction amount,discretized income etc.,
4) Hand annotated response classes “Default”,”Non Default” for a sample of customer records using the business rules to create training labels
5) Explored several attributes of customer such as age,income,number of loans,sex,credit score etc., w.r.to response variable
6) Modeled logistic regression for the classification to interpret the variable importance based on odds ratio and decision tree model to interpret variables ,derive decision rules based on tree structure
7) Evaluated model performance based on F1-Score and tree model outperformed logistic model ,hence as a next step Random Forest model was trained to achieve better results
8) Tested the model performance on future loan data, both logistic regression and Random forest achieved better F1 score than expert judgement by 0.15 this is because existing expert judgement over looked some dynamic variables like late fee
Published:
Key Words: R, Logistic Regression , GBM , tf-idf
This project is to classify email into SPAM , NOT SPAM and it is a in-class competition for the statistical learning course. Data set for the analysis can be found at UCI ML Repo , it contains normalized tf-idf of several important words that can discriminate an email into SPAM/NOT SPAM. As part of data exploration ,i) variable selection was performed based on the feature density plots ,ii) removed high correlations based on vif measure and iii) identified significant variables and their interactions by interpreting odds ratio from logistic regression. For the binary classification objective several machine learning models were used such as GLM, ElasticNet, GBM, Radial SVM with best set of variables and their interactions. Our feature selection with GLM and GBM model as classifier ranked top on the competition leader board.
Links : Git Repo
Published:
Key Words: Python, NLTK ,word2Vec, GloVe, SVR ,PCA
Triple-scoring task is to compute relevance scores for knowledge-base triples from type-like relations such as PERSON-PROFESSION-RELEVANCE SCORE or PERSON-NATIONALITY-RELEVANCE SCORE. For example, Julius Caesar has various professions, including Politician and Author. Given the (Julius Caesar,{ profession} Politician) triple and (Julius Caesar, {profession} Author) triple, the former triple is expected to have a higher relevance score (so called “triple score”) because politician is the major profession of Julius Caesar. Accurate estimation of such triple score benefits ranking for knowledge base queries. Since in the training data we just had three columns “Person”,”Profession”,”Score” so lot of feature engineering was performed to create vector space for training ,in our approach we propose to integrate knowledge from both latent features and explicit features with an ensemble method to address the problem. The latent features consist of person entities representations learned from word2vec model and profession/nationality values’ representations learned from GloVe model. In addition, we also incorporated the explicit features of person entities from the Freebase knowledge base and from Wikipedia. Experimental results show that our feature integration method with and Support Vector Machine algorithm training performed well and ranked 3rd place in the competition.
Methodology Paper was submitted to WSDM ,2017 conference
Title : “ Integrating Knowledge from Latent and Explicit Features for Triple Scoring”
Links : Git Repo
Published:
Key words : SAS, Descriptive Statistics , Logistic Regression, Discriminant Analysis
Health sciences is one of the areas where Data analysis plays a crucial role and it offers rich medical records data for the patients. By analyzing the patient’s historical data, we can find some interesting insights about a certain disease, which will benefit in predicting a new patient getting a similar disease. So, that we can take necessary actions possible to prevent the disease or else we can treat the disease effectively by identifying the major cause.
For this group project, Jay was the leader of the group and guide small team of under-graduate students.Our group choose to work on chronic heart disease and it is one of major disease that causes thousands of deaths. Through Data modelling on patient data we try to predict the chances of a patient getting chronic heart disease. Also, we figure out what are the major factors that cause heart disease, and tried to answer questions like
1) Is the heart disease depends on Age of the patient, then what is the age range that is more prone to the heart disease?
2) What are the effects of Smoking and drinking habits, and do they most likely cause heart disease
3) How obesity or cholesterol, effects the chances of getting a heart disease?
4) Does the heart disease depended on family history? i.e; If any family member has the heart disease then how likely it is, patient getting a heart disease.
Jay’s role in this project was to lead the team through guidance and discussions ,building predictive model for hereditary factor using Discriminant analysis and interpret ,visualize the effect of significant variables causing heart disease.More details can be found on links below
Links : Project report and Git Repository
Published:
Key words: R, h2o, XGboost,LASSO,PCA,K-Means Clustering
Insurance domain is one of the prominent domains where statistical learning/Machine learning plays a crucial role. With the use of statistical learning we can automate the process of claim-cost prediction and, also the severity. This automated process ensures a worry-free customer experience and offers insight into better ways to predict claims severity.
For this Group project, our task was to predict the target variable “loss” (numeric value) based on the several anonymous predictor variables which include 116 categorical variables,14 continuous variables. Considering the large dimension of data with over 180,000 observations and 130 predictor variables great deal of feature selection ,engineering was needed.
At first data exploration was performed for better understanding the problem using statistical tests and correlation analysis, then performed feature engineering using dimensionality reduction,clustering and feature selection using LASSO and Random Forest. Later modeled “loss” using XGboost , GBM ,LASSO with the selected important features.
Jay’s role in this project was to design the pipeline for the analysis and feature engineering using PCA (Numeric data) , K-Means clustering by using Gower-distance, Correlation Analysis and Modelling “loss” using XGboost algorithm.
Links : Project Report and Git Repo
Published:
Key words: R, h2o , XGboost ,Sparklyr
This Project is a competition on DRIVENDATA, to predict which pumps are functional, which need some repairs, and which don’t work at all. Predicting one of these three classes based on a number of variables about what kind of pump is operating, when it was installed, and how it is managed. A smart understanding of which water points will fail can improve maintenance operations and ensure that clean, potable water is available to communities across Tanzania.
Data cleaning was as performed such as
i) Removed some of the variables as they are constant or no variation
ii) Some variables are similar to others such as latitude and longitude variables conveys location information ,so other redundant location variables were removed
iii) Some categorical variables have too many levels and such variables were discarded
iv) created new variables to account for age of pump based on installation date etc.,
After feature engineering ,Classification model was trained using Xgboost and Random Forest using h2o, sparklyr packages and interpreted significant variables for classifying faulty water based on information gain.
Links : Git Repo
Published:
Key words: Python,SQL,APIs,web scraping,Selenium,pptx
This Project is about a tool called flash_ppt developed at Mayo clinic.Flash ppt is a software/tool written in python ,to automate the pptx genetic report generation process in data pipelines.
Back ground:
Genetic report contains information about gene variants from a subject/patient and it is used by Genetic counselors to analyse disease and provide counseling to patients. Genetic information comes from several sources such as multiple catalog files(from clinical labs across the world) and websites such as OMIM,NCBI,HGMD etc.,
At Mayo Genetic counselors prepares these reports manually typically it takes 3 hours to put together a single report .As report preparation is cumbersome so the whole process is automated in order to reduce the human effort.With automation a single report can be generated in less than a minute.
Links : Git Repo
Published:
Tools: Python, REST APIs, Docker, networkx, pandas
Methods:Several NLP and graph techniques such as
Published:
Tools: Python, REST APIs, Docker, Mongo DB, Watson Assistant
Methods:Several ML,NLP techniques such as
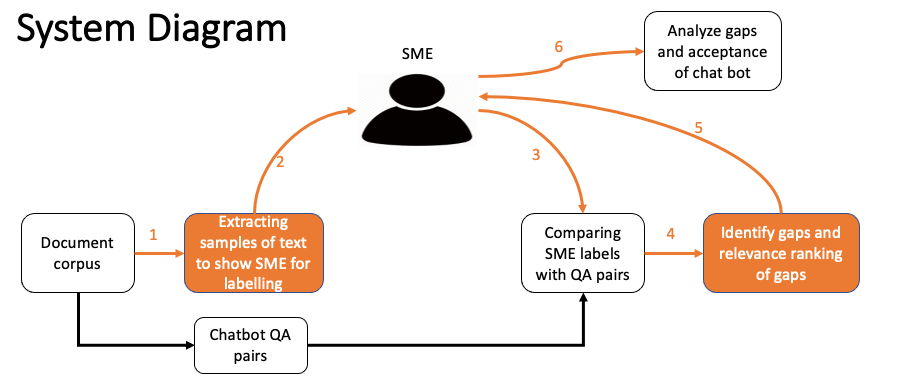
Published:
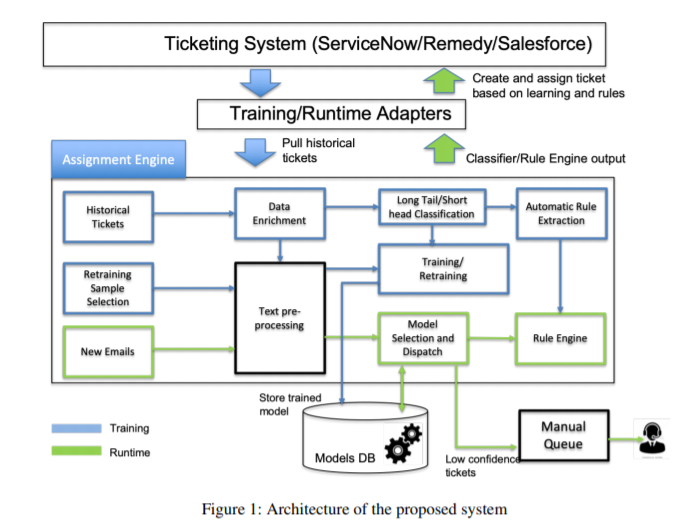
Tools: Python , docker , REST APIs , OpenShift , pm4py , networkx
Methods:Several Deeplearning and Statistical techniques such as
Published:
Tools: Python, REST APIs, Docker, Mongo DB
Methods:Several ML,NLP techniques such as
Published:
Tools: Python, REST APIs, Docker, Elastic Search , Mongo DB, Watson Discovery , Watson Assistant.
Methods:Several NLP techniques such as
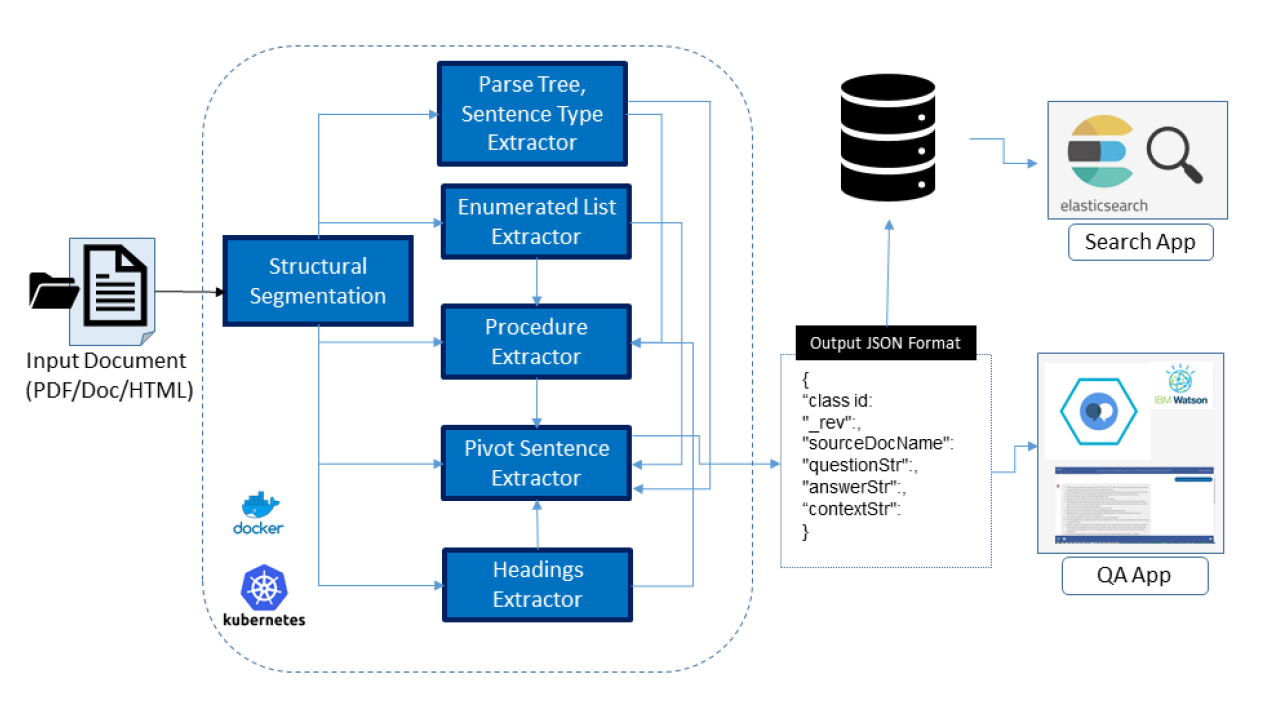
Published:
This section is about useful R and Python scripts for Data analysis,Machine learning and web scraping.
1) New York Times web scraper.R script for web scraping NYT API, input custom Search Term like “Immigration”, Start Date and run script to save articles data into CSV file.
2) Data Viewer Simple data viewing application using R, Shiny.Useful for reading text files with large content and input your text file in CSV format.
3) R_basics.R template script for Regular Expressions, dplyr and functional programming in R.
4) Python-programming repo : Repository for python programming includes data structures,algorithms implementations.
5) Caret_models.R template for several machine learning models such as Elasticnet, GBM ,SVM with cross validation using R “caret” package.
6) h2o_ensemble.R script for faster ensemble learning using several h2o models such as GLM.RF,GBM for binary classification.
7) Pathsim.py similarity measure algorithm for finding and ranking similar authors based on DBLP publications uni-directional graph structures such as Author-Venue-Paper.
8) ML Algorithm Implementations:
Decision Tree, Random Forest in python
Apriori for Frequent Patterns in python
K Nearest Neighbors in python
Naive Bayes in R
Discriminant Analysis in R